
Sample Design Methods
Sample design methods generally refer to the technique used to select sample units for measurement (e.g., select individuals from a population or locations to sample within a study area). Before sample design methods can be considered, it is necessary to have thoroughly defined the population, study area, sampling unit, and sampling objective. All of these will have an impact on which sample design methods are suitable. Selection of a suitable sample design method ensures that the samples you invest your time and money into collecting can support the inferences you want to make. Use of a sample design method that is not appropriate can lead to samples that are biased with respect to your assessment or monitoring objectives. In this case, inference is valid only for samples/sites that were measured, and not the larger area/population.
Sample design methods are typically divided into two types: Non-random and random methods. These two types and commonly-applied methods within each are discussed below. It is not uncommon for sample design for a single project to include aspects of random and non-random selection. For example, sample site locations may be selected randomly within a study area, but the transects or plots to be sampled within the site may be located systematically. In this case, the randomization of the site locations can preserve the statistically-unbiased nature of the overall sample design. However, just because randomization is included at some point in the sample design doesn’t guarantee good sample design. Selecting site locations non-randomly based on local knowledge and then randomizing the locations of plots within each site will not result in a statistically unbiased sample. Attention must be paid to where the randomization occurs relative to the distribution of the population being sampled to ensure that the overall sample design maintains the desired statistical properties.
Non-Random Sampling Methods
Non-random sampling methods select locations for sampling by either: according to regular (i.e., systematic) patterns, targeting specific features or events, using personal or anecdotal information, or without any specific plan. Care must be exercised when using non-random sample selection methods because the samples may not be representative of the entire population. If this is the case, then inference cannot extend beyond the set of sampling units. Some common non-random sample design techniques are discussed below. Unless otherwise stated, the primary reference for these discussions was Elzinga et al. (2001).
Systematic Sampling
Systematic sampling is the selection of units for sampling or the placement of sampling locations within an area according to a regularly-repeating pattern. Examples of systematic sampling are: locating sample sites on a 1km grid within a pasture, taking measurements every meter along a transect, or orienting transects along cardinal directions. Systematic techniques are commonly used to locate sub-plot sampling sites (e.g., points, transects, frames) within a sampling site where the location of the sampling site has been selected randomly. Alternatively, larger sampling units can be selected systematically and then the location of the specific sampling unit randomly selected within the larger unit (i.e., a form of two-stage sampling or restricted random sampling – see below). This technique is often used with regional- or national-scale assessment and monitoring programs like the NRCS Natural Resource Inventory (NRI) or the USFS Forest Inventory and Analysis (FIA) programs.
Advantages of systematic sampling are:
- it allows even sampling across an area
- it is quick and easy to implement
- it is often more efficient than random sampling, and can perform as well or better than random methods in some situations (see Elzinga et al. (2001), p125)
- When combined with an appropriate randomization method, the data can be analyzed as if it were a random design
Disadvantages of systematic sampling are:
- it can yield biased data if there are regularly-occurring patterns in the population being sampled. For instance, when sampling for road impacts, transects oriented along cardinal directions may yield biased estimates of road impacts because many roads are oriented along cardinal directions too (M. Duniway, pers. comm.)
- systematic sampling can miss or under-represent small or narrow features of a landscape if the sampling interval is too large.
Selected/Targeted Sampling
Targeted or selected sampling is common in rangeland assessment and monitoring. With this method, areas are subjectively selected for sampling according to a particular objective. The subjective nature of selecting the sampling locations, however, can easily introduce bias into the results and preclude being able to assess sampling errors. For these reasons, it is not appropriate to extent inference of sampling results beyond the elements sampled to the whole population. For a random sampling method that can, in some cases, achieve the same end as targeted sampling (i.e., selection of areas representative of some specified condition), see Unequal Probability Sampling below.
The key area concept is a form of non-random targeted sampling. The idea of key areas is to select locations for sampling that are representative of either a larger area (e.g., an allotment or pasture) or to critical areas (e.g., high impact sites or locations where rare species occur). Assessment and monitoring then takes place in these locations. Because statistical inferences can only be made to the key areas that are sampled, and because sampling results from different key areas cannot be averaged, objectives should be defined specific to the key areas being measured.
Targeted sampling is also common in remote-sensing applications. When creating a land-cover or vegetation-class map from remotely-sensed imagery, field observations are often needed to “train” the classification algorithm to the classes being mapped. In these cases, statistical inference of the field observations to the entire population is not an objective of the sampling. Areas are selected in a targeted manner to represent the range of variability within each class and for ease in data collection in the field. Use of a randomization method of sample design for this type of remote sensing application would be an inefficient way to get the needed data.
Advantages of targeted sampling
- allows for efficient collection of data in situations where statistical inference is not required
Disadvantages of targeted sampling
- Statistical inference beyond the units actually sampled is invalid
- Inability to combine data from different key areas
Haphazard Sampling
Haphazard sampling occurs when samples are collected in the field without any pre-determined method for deciding where to sample. In essence, this approach is the de facto method when no other method was used. It probably could go without saying that haphazard sampling leads to data that cannot be used to make inferences to other areas or a larger population, and this method should be avoided for assessment and monitoring. Data collected with this technique is considered anecdotal information.
Random Sampling Methods
Random sampling methods rely on randomization at some point in the sample design process in an attempt to achieve statistically unbiased samples. Random sampling methods are a form of design-based inferencewhere 1): the population being measured is assumed to have fixed parameters at the time they are sampled, and 2) that a randomly-selected set of samples for the population represents one realization of all possible sample sets (i.e., the sample set is a random variable). There are many different random sampling techniques. Some of the most common techniques are described below. Unless otherwise stated, the primary source for information on these methods is Elzinga et al. (2001).
Simple Random Sampling
Simple random sampling is the foundation for all of the other random sampling techniques. With this approach, all of the sampling units are enumerated and a specified number of sampling units are selected at random from all the sampling units. Selection of samples for simple random sampling follow two criteria:
- each sampling unit has the same likelihood of being selected, and
- the selection of one sampling unit does not influence the selection of any other sampling unit.
Simple random selections are easy and fast to implement using a variety of GIS, statistical, or spreadsheet programs.
Advantages of simple random sampling
- it is the easiest of the random methods to implement
- the statistical formulas for estimating population parameters are well known and easy to implement
Disadvantages of simple random sampling
- it does not take into account variability caused by other measurable factors (e.g., aspect, soils, elevation)
- it can yield high variance estimates and make detection of differences difficult if the population being sampled is not evenly distributed throughout the sample area.
- it can be an inefficient means of sampling because of the time required to visit all of the sample sites
- by chance, some areas may be heavily sampled while other areas are not sampled at all
Stratified Random Sampling
Stratification is the process of dividing a set of sampling units into one or more subgroups (i.e., strata) prior to selection of units for sampling. Sampling units are then selected randomly within each stratum. The purpose of using stratification is to account for variability in a population that can be explained by another variable (e.g., vegetation type, aspect, soil type). Therefore, strata should be defined so that the population conditions are similar within the strata.
Sampling effort does not need to be equally allocated between strata. It is common for sampling intensity to be varied between strata based on either the variability of the population parameter within the strata or the size of the strata.
Advantages of stratified random sampling
- it increases efficiency of sampling over simple random sampling when the variable of interest responds differently to some clearly definable features.
Disadvantages of stratified random sampling
- the formulas for estimating population parameters and conducting hypothesis tests are more complicated than for simple random selection.
- each stratum should be relatively homogeneous with regard to the population parameter being measured.
Restricted Random Sampling
In restricted random sampling, the area to be sampled is divided up into large segments based on the number of sampling units needed to meet monitoring objectives. Within each segment, a single sampling unit is then selected (i.e., a single sampling location is selected) at random. The samples are analyzed as if they were collected using the simple random sampling technique. This technique helps ensure good coverage of points within a study area. Many GIS random-point-generation tools include a derivation of this technique – enforcing a minimum distance between sample points.
Restricted random sampling has similarities to both systematic sampling and stratified random sampling. The distinctions however, are that: 1) while the segments into which the population was divided are technically a form of stratification, they are arbitrary with respect to the system and only one sample is collected per segment, and 2) the area need not be divided into equally spaced or shaped segments like would be the case in systematic sampling.
Advantages of restricted random sampling are:
- good dispersion of sampling points across an area
- more efficient sampling than simple random sampling
- Easy to implement with GIS tools
Disadvantages of restricted random sampling are:
- it is possible for sample points to end up close to each other (i.e., each on opposite sides of a shared segment boundary) and leave a large area unsampled.
Unequal Probability Sampling
One of the main assumptions for simple random sampling is that all sampling units have an equal likelihood of being selected for sampling. However, as discussed with a number of the other sample design techniques, this can lead to inefficiencies in sampling, especially if the sampling objective is to focus on a subset of the population or there are logistical constraints in getting to some portions of the total area. In these cases, non-random targeted (e.g., key area) sampling becomes tempting. An alternative to simple random sampling that can help address some of these issues is sampling with unequal selection probabilities.
Basically, this method works in a similar manner to simple random sampling except that the sampling units have different probabilities of being selected. How the selection probabilities are determined and assigned to the sampling units is not as important as is the knowledge of the selection probability assigned to EVERYsampling unit. Accordingly, samples can be weighted toward “representative” or “critical” areas or assigned to give preference to sampling units that are within easily accessible regions of the study area. Preferentially selecting units for sampling introduces bias into the sampling results, but the fact that we know the likelihood associated with selecting each sampling unit allows for the bias to be corrected for. In essence, individual samples are weighted according to their selection probability – samples with a high likelihood of being selected have a low weight, and samples that are unlikely to be selected carry a higher weight.
Sampling with unequal selection is commonly applied in forestry surveys as sampling with probability proportional to size. Consider the example of needing to estimate the total board-feet of timber in a stand. Board-feet is correlated to diameter of the tree, so assigning selection probabilities according to the diameter of the trees in the stand allows the observer to measure a few large trees and expand those results to the entire stand using a correction (a.k.a. expansion factor) calculated from the selection probabilities.
The probability-proportional-to-size concept can be generalized to probability proportional to a covariate. In rangeland situations, many of the parameters of interest are correlated with different remote-sensing products. These image products can be used to calculate selection probabilities. For instance, if “key area” samples (i.e., representative of a larger area) are desired, a greenness index such as NDVI could be used to assign selection probabilities such that extreme conditions received low selection probabilities and the most typical areas received the highest selection probabilities.
Advantages of Unequal Probability Sampling
- Allows for more efficient random sampling than simple random sampling does
- Allows for sampling to be focused on areas/conditions of interest or according to logistical constraints.
- Bias introduced by targeted sampling can be corrected for
Disadvantages of Unequal Probability Sampling
- Selection probabilities must be defined for every area that possibly could be sampled
- The calculations for correcting for bias are complicated and not many statistical programs contain easy-to-use tools for handling unequal probability sampling data yet.
See Horvitz and Thompson (1952), Saxen et al. (1986), Rosen (1997) and Berger (2004) for more information
Adaptive Sampling
Adaptive sampling refers to a technique where the sample design is modified in the field based on observations made at a set of pre-selected sampling units. Perhaps the best way to describe adaptive sampling is through an example. Consider sampling for the presence or abundance of rare plants. A random selection of sample units will yield many sample units where the plant is not detected, but the rare plant is likely to occur in sample units nearby to those units where it was detected. With adaptive sampling, the detection of the rare plant at one site triggers the selection and sampling of additional nearby sites that were not originally selected as part of the sample set. Thus the biggest difference between adaptive sampling and many other random selection techniques is that the observed conditions at one sampling unit influence the selection of other sampling units.
One typical implementation of adaptive sampling is that whenever a specified event occurs (e.g., detection of a target species, measurement over a specified threshold), all of the neighboring sample units are searched/sampled. This continues until no new detections occur.
Adaptive sampling introduces bias into the samples that must be corrected for. More specifically, adding additional units to the sample that contain high values for the parameter being measured will result in overestimation of the population mean (Thompson 1992). Various techniques are available for correcting for the bias introduced by adaptive sampling.
Advantages of Adaptive Sampling
- It is an efficient method for sampling rare species or events
- It works well with populations that are naturally aggregated or clustered and does not require the exact nature of the aggregation to be known ahead of time
Disadvantages of Adaptive Sampling
- Population estimates must be corrected for bias.
- Calculations for population parameter estimates and hypothesis tests are more complicated than for simpler sampling designs.
- Estimation of sample size requirements is difficult.
See Thompson (1992), Thompson and Thompson and Seber (1996), and Prather (2006) for details on adaptive sampling.
Cluster Sampling
Cluster sampling is a technique that can be applied when it is not possible or desirable to take a random sample from the entire population. With cluster sampling, the known or accessible sampling units are grouped into clusters. A random selection of clusters is then made and each sampling unit is measured within each of the selected clusters. Cluster sampling is typically applied to monitoring of rare plants or invasive species when the objective is to estimate a property related to individual plants (e.g., mean height, number of flowers per plant).
Advantages of cluster sampling are:
- It can be less expensive and more efficient to sample all of the sampling units within a cluster than to sample an equal number of units across the entire population.
- Cluster sampling can be an efficient choice when clusters naturally occur and when the clusters are similar to each other but have a high degree of internal variability
Disadvantages of cluster sampling are:
- all elements within the selected clusters must be measured. If clusters are large or contain a large number of elements, then two-stage sampling may be more efficient.
- It can be difficult to determine how many clusters to sample versus how large the clusters should be.
- Analysis of sample data collected using a cluster analysis design is more complex than other methods.
Two-Stage Sampling
In two-stage sampling, elements of the population are grouped together into large groups called primary sampling units. The individual sampling units within each primary sampling unit are called secondary sampling units. A random selection of the primary sampling units is made, and then a selection of secondary sampling units is made (usually random, but can be systematic) within each of the selected primary sampling units.
Two-stage sampling is a powerful sample design method for systems that are hierarchical in nature. For example, allotments within a BLM District could be considered primary sampling units. A random selection of allotments could be made and then sample sites selected within the selected allotments. This design would allow for inference at the allotment level (e.g., average allotment condition) as well as at the district level.
The concept of two-stage sampling can be generalized to multi-stage sampling where there are more than two hierarchical levels for sampling. However, as the number of stages increases, sample size requirements go up and degrees of freedom for statistical hypothesis testing decrease. Accordingly, the number of stages is generally small (i.e., two or three).
Advantages of two-stage sampling are:
- It is often more efficient to sample secondary sampling units within a limited number of primary sampling units than to sample the same number of secondary units randomly spread across a landscape.
- Inferences can be made at multiple scales (i.e., the scale of the primary sampling unit, and the entire population).
Disadvantages of two-stage sampling are:
- Calculation of sample statistics is more complicated than with other simpler sample designs.
Double Sampling
Double sampling (also called two-phase sampling – not to be confused with two-stage sampling above) involves estimating two correlated variables. This method would be used in cases where the primary variable of interest is expensive or difficult to measure, but a secondary covariate is easily measurable. A small number of sample units are randomly selected and both variables are measured at these locations. The secondary variable only is then measured at a larger number of randomly selected points. The success of a double-sampling sample design depends on how well correlated the primary and secondary variables are.
Double-sampling is commonly used in estimation of above-ground biomass in rangelands. Clipping and weighting of vegetation is expensive and tedious. With the double-sampling method, ocular estimates of biomass are made for a small number of quadrats, and the vegetation on those quadrats is then clipped and weighed. For the remaining quadrats, only the ocular estimates are performed.
Advantages of double sampling are:
- it can be much more efficient than directly sampling the primary variable if the secondary variable can be measured quickly and it highly correlated with the primary variable.
Disadvantages of double sampling are:
- the formulas for data analysis and sample size estimation are much more complex than for some other methods.
Spatially-balanced Sampling
Spatially-balanced refers to samples that are evenly distributed across a study area. Spatially balanced sampling is much more efficient than simple random sampling if the population being sampled is more-or-less evenly distributed across the area being sampled. While a systematic sample design can achieve complete spatial balance, it lacks randomization that is desirable in statistical sample designs and it is difficult to apply when the units being selected for sampling are not contiguous within the study area (e.g., selecting lakes or wetlands to sample).
There are several different techniques for creating spatially-balanced sample designs, but one of the most common ones is the Generalized Random-Tessellation Stratified (GRTS) design described by Stevens and Olsen (2004). For sampling within an area, the GRTS technique works as follows:
- The sampling units are assigned an order according to a recursive, hierarchical randomization process (see figure for example and explanation). This process preserves the spatial relationships of the sample units.
- The sampling units are then arranged in order (think of arranging them in a line)
- The line of sampling units is divided into a number of equal-length segments depending on how many total samples are desired
- One sampling unit from each segment is selected for sampling.
The GRTS method produces samples that are spatially-balance. It also has the interesting property that each subsequent sample location selected using GRTS will be spatially-balanced with respect to the previous points. The benefit of this is that an “oversample” of sampling units can be drawn (e.g., draw a sample of 30 units when you only intend to sample 20) and if one unit needs to be thrown out for some reason (e.g., access restrictions), then the next selected unit (sample unit 21 in the example above) will maintain the statistical properties of the original 20 sample units.
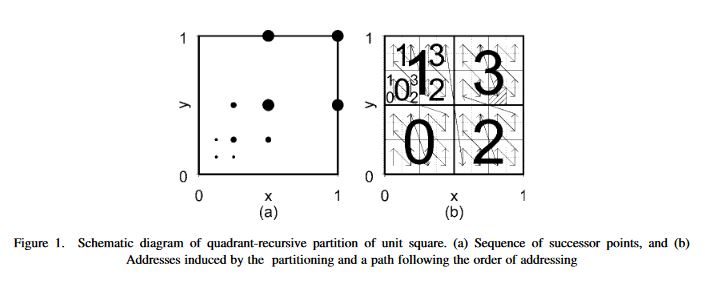
Stevens and Olsen (2004)
An example of a recursive, hierarchical randomization process applied to an area to be sampled. This process is used to assign the random, but spatially-balanced order to the sampling units. The area is first split into four quadrats. Each quadrat is then split into four smaller quadrats, and so on until there is only one sampling unit per quadrat (or until the size of the quadrats equals the desired distance between samples). The sample units are then ordered according to the numbering assigned to the quadrats. In this example, the main quadrats and the sub-quadrats have the same number ordering, but in practice, random numbering is assigned for each quadrat level.
Advantages of Spatially-Balanced Sampling (using GRTS)
- It is a probability-based sampling technique that maintains good spatial balance
- Oversampling can be used to provide “fall-back” sampling locations in case the original sample locations need to be thrown out.
- Can be used for sampling areas, but also can be used with linear features or features that are not contiguous
- Supports sampling with unequal selection probabilities
Disadvantages of Spatially-Balanced Sampling (using GRTS)
- It is a complicated technique to understand and difficult to implement
- If the estimation of spatial autocorrelation of population parameters is desired (i.e., for geostatistical techniques), spatially-balanced sampling is inefficient
See Stevens and Olsen (2003, 2004) for details of GRTS
Sources of Additional Information
- Herrick et al. (2009) include a chapter on sample design and sample size calculations in their monitoring manual.
- Bureau of Land Management. 1996. Sampling vegetation attributes: interagency technical reference. BLM/RS/ST-96/0002+1730 has a section on sample design considerations.
- US EPA Aquatic Resources Inventory has a page on applications of spatially balanced sampling to different natural resource applications. This site provides examples, references, links to detailed descriptions, and code/software downloads.
- The University of Idaho College of Natural Resources maintains a basic statistics website for natural resources students. This site is a good source of basic statistics info for those needing a refresher or primer.
- See the Methods Guide wiki page for Colorado State University’s Spatially Balanced Sampling in GIS using RRQRR
References
- Berger, Y. G. (2004). A simple variance estimator for unequal probability sampling without replacement. Journal of Applied Statistics 31(3) 305-315.
- Bonham, C.D. 1989. Measurements for terrestrial vegetation. John Wiley & Sons, New York, NY. p 265.
- Elzinga, C. L., D. W. Salzer, and J. W. Willoughby. 1998. Measuring and monitoring plant populations. U.S. Department of the Interior, Bureau of Land Management. National Applied Resource Sciences Center, Denver, Colorado.
- Gregoire, T. G. 1998. Design-based and model-based inference in survey sampling: appreciating the difference. Canadian Journal of Forest Research 28:1429-1447.
- Horvitz, D.G. & Thompson, D.J. (1952). A generalization of sampling without replacement from a finite universe. Journal of the American Statistical Association 47(260): 663-685.
- Prather, T. (2006). Adaptive sampling design. //in// L. J. Rew, and M. L. Pokorney, editors. Inventory and survey methods for nonindigenous plant species. Montana State University Extension, Bozeman, MT.
- Rosén, B. (1997). On sampling with probability proportional to size. Journal of Statistical Planning and Inference 62: 159-191.
- Saxena, R.R., Singh, P. and Srivastava, A.K. (1986). An unequal probability sampling scheme. Biometrika 73(3): 761-763.
- Stevens, D. L., Jr., and A. R. Olden. 2003. Variance estimation for spatially balanced samples of environmental resources. Envirometrics 14:593-610.
- Stevens, D. L., Jr., and A. R. Olden. 2004. Spatially balanced sampling of natural resources. Journal of the American Statistical Association 99:262-278.
- Theobald, D. M., D. L. Stevens, Jr., D. White, N. S. Urquhart, A. R. Olsen, and J. B. Norman. 2007. Using GIS to generate spatially balanced random survey designs for natural resource applications. Environmental Management 40:134-146.